Final
| 内容 | 分值 | 负责助教 | 备注 |
|---|---|---|---|
| Console | 10 | 徐厚泽 | |
| Pipe | 5 | 徐厚泽 | O |
| File Descriptor | 15 | 唐傑伟 | |
| Shell | 15 | 唐傑伟 | |
| Exec | 20 | 孔令宇 | |
| Fork | 10 | 孔令宇 | |
| Memory Management | 15 | 孔令宇 | |
| Mmap | 10 | 孔令宇 | O |
| 自选 Bonus | 20 | TBC | O |
INFO
说明
O:不实现此部分也可以启动 shell。如果时间来不及,请优先保证你能启动 shell,因为启动 shell 所占分值较大。建议优先完成:File Descriptor + Exec + Fork + Shell + Console + Pipe。- 满分 100 分,超出的部分算 bonus。
1. File Descriptor
在这一部分,我们将完成和文件(file)以及文件描述符有关的最终实现。
你也许有疑问:为什么已经有了完整的硬盘文件/目录抽象(inode),还需要再包装一层?答案正如我们所常说:UNIX 的设计哲学是一切皆文件,除了狭义上的硬盘上的“文件”,我们还有设备文件(device File)和管道文件(pipe file)等等。这些文件的特点是:它们不是硬盘上的文件,而是内核中的一些数据结构,但和硬盘文件一样都可以作为读写操作的对象。
因此,我们需要为它们再设计一套抽象,使得用户态程序可以通过同一套机制来访问它们中的任何一个。这套机制就是文件(file)。
INFO
从面向对象的角度理解"一切皆文件"
从面向对象的角度来看,"一切皆文件"可以将"文件"这一概念视为一个抽象类(abstract class)或接口(interface)。这一理念的核心在于通过一套统一的接口操作多种资源。这一原则不仅能够最大限度地复用已有代码,还具备良好的可扩展性,符合软件工程中久经验证的优秀实践之一:开闭原则(OCP)。
在 Linux 系统中,这套接口的实现通过以下结构体定义:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
};支持该接口的资源通常以数据为中心。例如:
- 键盘作为字符设备,管理用户输入的字符数据。
- 管道文件管理一段由某进程输出、供另一进程输入的数据。
/dev/random设备管理随机数据。
文件除了需要持有底层对象以外,还有一些额外的字段:
- 文件以偏移量(对于硬盘文件就是从文件开头的字节数,对于设备文件和管道文件就是迄今为止读/写的字节数)来标识当前读写的位置;
- 文件为了能同时被多个进程持有,需要记录当前持有者的数量;
- 文件还需要记录当前可行的读写模式(例如,设备文件可能仅能以只读模式打开,管道文件可能一头只写、一头只读,没有权限写的硬盘文件可能也仅能以只读模式打开)。
为了节省不必要的开支,所有的文件对象被组织在一个全局文件表中(一个数组),而每个进程又有自己的进程文件表(同样是一个数组)。进程文件表中,每个文件对象都有一个文件描述符(file descriptor)来标识自己。文件描述符是一个非负整数,即进程文件表中的下标,通过它可以找到对应的文件对象。
一个极简的文件对象如下所示:
enum file_type {
NONE, // 未使用
DEVICE, // 设备文件
INODE, // 硬盘文件
PIPE, // 管道文件
};
struct file {
enum file_type type; // 文件类型
bool readable, writable;// 读写模式
int refcnt; // 当前持有者数量
usize offset; // 当前读写偏移量
union {
struct inode *inode; // 硬盘文件的下层接口(Inode)
struct device *device; // 设备文件的下层接口(Device)
struct pipe *pipe; // 管道文件的下层接口(Pipe)
};
};值得注意的是,在本实验中我们进行了一些简化和修改:
我们支持的外设很少(只有一个终端字符设备),而且我们目前还没有做出虚拟文件系统(VFS)的接口,因此为简便起见,我们不再为设备(device)设计一个单独的抽象,而是直接复用硬盘的 inode 抽象,将其看作设备文件的下层接口。 也就是说,当我们创建一个设备文件时,我们将在硬盘上创建一个实在的 inode,其类型为 INODE_DEVICE。因此,你的inode 接口也要考虑到设备文件的情况(例如 inode_read 等函数可能调用设备文件的下层接口,如 console_read)。当然,这是后话了。
1.1. 任务
IMPORTANT
任务 1:实现 src/fs/file.c 的下列函数:
// 从全局文件表中分配一个空闲的文件
struct file* file_alloc();
// 获取文件的元信息(类型、偏移量等)
int file_stat(struct file* f, struct stat* st);
// 关闭文件
void file_close(struct file* f);
// 将长度为 n 的 addr 写入 f 的当前偏移处
isize file_read(struct file* f, char* addr, isize n);
// 将长度为 n 的 addr 从 f 的当前偏移处读入
isize file_write(struct file* f, char* addr, isize n);
// 文件的引用数+1
struct file* file_dup(struct file* f);
// 初始化全局文件表
void init_ftable();
// 初始化/释放进程文件表
void init_oftable(struct oftable*);
void free_oftable(struct oftable*);IMPORTANT
任务 2:截止目前我们都未编写路径字符串(例如 /this/is//my/path/so_cool.txt)的解析逻辑。我们在 src/fs/inode.c 中实现了比较困难的部分,你需要完成其中的namex函数(可见inode.c中的注释部分):
static Inode* namex(const char* path, bool nameiparent, char* name, OpContext* ctx)IMPORTANT
任务 4:实现辅助函数:
// 从描述符获得文件
static struct file *fd2file(int fd);
// 从进程文件表中分配一个空闲的位置给 f
int fdalloc(struct file *f);
// 根据路径创建一个 Inode
Inode *create(const char *path, short type, short major, short minor, OpContext *ctx);IMPORTANT
任务 5(可以以后再做):参考讲解部分,修改 inode.c 中 read 和 write 函数,以支持设备文件。
2. Fork & Exec
fork 和 execve 是 Unix/Linux 系统编程中两个核心的系统调用,用于创建新进程和执行新的程序。fork 用于从当前进程(父进程)中创建一个新进程(子进程),而 execve 用于在当前进程中执行一个新程序。fork 和 execve 的组合使用是实现多进程和加载新程序的核心机制。在本部分中,我们将实现 fork 和 execve 系统调用,为后续启动 shell 做好准备。
2.1. ELF 可执行文件格式
ELF 文件描述了一个程序。它可以看作一个程序的“镜像”,就像 ISO 文件是一个光盘的“镜像”一样。ELF 文件包含程序的入口地址、各个段的大小、各个段的属性(可读、可写、可执行等)等等。我们按照这些信息,将程序加载到内存中,然后跳转到入口地址,就可以运行这个程序了。
在本部分中,我们需要实现 ELF 文件的解析和加载。后续,我们运行用户程序(如 ls, mkdir 等)前都需要加载其 ELF 到内存中。在这里,我们给出两个会用到的结构体定义(相关头文件:musl/include/elf.h):
/**
* ELF Header:ELF 文件的入口点,位于文件的开头,描述了文件的整体布局和重要属性。
*/
typedef struct {
// 标识 ELF 文件的魔数、架构类型(32/64 位)、字节序(小端/大端)等。
unsigned char e_ident[EI_NIDENT];
// 文件类型(可执行文件、共享库、目标文件等)。
Elf64_Half e_type;
// 指定目标机器架构(如 x86、ARM)。
Elf64_Half e_machine;
// ELF 版本信息。
Elf64_Word e_version;
// 程序入口地址(可执行文件运行时的起始地址)。
Elf64_Addr e_entry;
// 程序头表(Program Header Table)的偏移量。
Elf64_Off e_phoff;
// 段头表(Section Header Table)的偏移量。
Elf64_Off e_shoff;
Elf64_Word e_flags;
Elf64_Half e_ehsize;
Elf64_Half e_phentsize;
Elf64_Half e_phnum;
Elf64_Half e_shentsize;
Elf64_Half e_shnum;
Elf64_Half e_shstrndx;
} Elf64_Ehdr;
/**
* Program Header Table (PHT):描述程序运行时需要加载的段信息,主要用于可执行文件和共享库。
*/
typedef struct {
// 段类型(如加载段、动态段、解释器段等)。
Elf64_Word p_type;
// 段的权限(可读、可写、可执行)。
Elf64_Word p_flags;
// 段在文件中的偏移量。
Elf64_Off p_offset;
// 段的虚拟地址(内存中的地址)。
Elf64_Addr p_vaddr;
// 段的物理地址(针对嵌入式设备)。
Elf64_Addr p_paddr;
// 段在文件中的大小。
Elf64_Xword p_filesz;
// 段在内存中的大小(可能大于文件中大小)。
Elf64_Xword p_memsz;
// 段的对齐要求。
Elf64_Xword p_align;
} Elf64_Phdr;WARNING
注意:ELF 文件中的 section header 和实验中的 struct section 并不一样,本次实验不用考虑 ELF 中的 section header,但是需要明确 ELF 中的 Elf64_Phdr 与 lab 中 struct section 的对应关系。
INFO
提示:可以参考 xv6 加载 ELF 的实现。
2.2. fork() 系统调用
计算机系统基础(ICS)复习:用户程序调用 fork() 将创建一个当前进程的完整复制,我们通过 fork() 的返回值区分亲进程和子进程(亲进程的返回值是子进程的 PID ,子进程的返回值是 0)。
在实现 fork() 的内核侧时,我们需要从进程的结构体(Proc)入手,判断其中的成员是否需要复制,是否需要修改。例如,我们需要深拷贝亲进程的页表给子进程,需要“复制”亲进程的文件描述符给子进程等。
INFO
思考:文件描述符的"复制"是什么意思?
WARNING
注意:为了配合 fork(),你可能需要在原先的 UserContext 中加入所有寄存器的值。此外,你还需要保存tpidr0 和 q0,因为musl libc会使用它们。
INFO
提示:可以参考 xv6 fork 的实现。
2.3. execve() 系统调用
/**
* @path: 可执行文件的地址。
* @argv: 运行文件的参数(即 main 函数中的 argv )。
* @envp: 环境变量
*/
int execve(const char* path, char* const argv[], char* const envp[])execve() 替换当前进程为 path 所指的 ELF 格式文件,加载该 ELF 文件,并运行该程序。你需要读取 Elf64_Ehdr 和 Elf64_Phdr 结构,注意根据 p_flags 的信息判断 section 类型,把 p_vaddr, p_memsz, p_offset 等信息填入到实验框架中的 struct section 对应位置;将文件中的代码和数据加载到内存中,并设置好用户栈、堆等空间;最后跳转到 ELF 文件的入口地址开始执行。
INFO
思考:替换 ELF 文件时,当前进程的哪些部分需要释放,哪些部分不需要?
INFO
思考:是否需要把 argv 和 envp 中的实际文本信息复制到新进程的地址空间中?
INFO
提示:下面提供了一个 execve 的大致流程:
/*
* Step1: Load data from the file stored in `path`.
* The first `sizeof(struct Elf64_Ehdr)` bytes is the ELF header part.
* You should check the ELF magic number and get the `e_phoff` and `e_phnum` which is the starting byte of program header.
*
* Step2: Load program headers and the program itself
* Program headers are stored like: struct Elf64_Phdr phdr[e_phnum];
* e_phoff is the offset of the headers in file, namely, the address of phdr[0].
* For each program header, if the type(p_type) is LOAD, you should load them:
* A naive way is
* (1) allocate memory, va region [vaddr, vaddr+filesz)
* (2) copy [offset, offset + filesz) of file to va [vaddr, vaddr+filesz) of memory
* Since we have applied dynamic virtual memory management, you can try to only set the file and offset (lazy allocation)
* (hints: there are two loadable program headers in most exectuable file at this lab, the first header indicates the text section(flag=RX) and the second one is the data+bss section(flag=RW). You can verify that by check the header flags. The second header has [p_vaddr, p_vaddr+p_filesz) the data section and [p_vaddr+p_filesz, p_vaddr+p_memsz) the bss section which is required to set to 0, you may have to put data and bss in a single struct section. COW by using the zero page is encouraged)
* Step3: Allocate and initialize user stack.
* The va of the user stack is not required to be any fixed value. It can be randomized. (hints: you can directly allocate user stack at one time, or apply lazy allocation)
* Push argument strings.
* The initial stack may like
* +-------------+
* | envp[m] = 0 |
* +-------------+
* | .... |
* +-------------+
* | envp[0] | ignore the envp if you do not want to implement
* +-------------+
* | argv[n] = 0 | n == argc
* +-------------+
* | .... |
* +-------------+
* | argv[0] |
* +-------------+
* | argc |
* +-------------+ <== sp
* ## Example
* sp -= 8; *(size_t *)sp = argc; (hints: sp can be directly written if current pgdir is the new one)
* thisproc()->tf->sp = sp; (hints: Stack pointer must be aligned to 16B!)
* The entry point addresses is stored in elf_header.entry
*/INFO
提示:在execve()中,一般可执行文件中可以加载的只有两段:RX的部分+RW的部分(其它部分会跳过)(因此只设置两种状态,一种是RX,另一种是RW)
- RX的部分: 代码部分,主要包括 text 段,属性为 ST_FILE + RO
- RW的部分:数据部分,包括了 data + bss 段
2.4. copyout
copyout 复制内容到给定的页表上,在 execve 中,为了将一个用户地址空间的内容复制到另一个用户地址空间上,可能需要调用这样的函数。如果你使用其他实现,则不需要实现这个函数。
/*
* Copy len bytes from p to user address va in page table pgdir.
* Allocate a file descriptor for the given file.
* Allocate physical pages if required.
* Takes over file reference from caller on success.
* Useful when pgdir is not the current page table.
* return 0 if success else -1
*/
int copyout(struct pgdir* pd, void* va, void *p, usize len)2.5. 任务
IMPORTANT
任务 1:实现下列内容:
kernel/syscall.c中的user_readable和user_writeable:检查syscall中由用户程序传入的指针所指向的内存空间是否有效且可被用户程序读写。kernel/proc.c中的fork。kernel/exec.c中的execve。kernel/pt.c中的copyout(可选)。kernel/paging.c中的copy_sections。kernel/paging.c中的init_sections:不需要再单独初始化 heap 段。kernel/paging.c中的pgfault:增加有关文件的处理逻辑。
3. Shell
本部分我们将尝试启动 shell 。
3.1. 任务
IMPORTANT
任务1:补全两个用户态程序的实现:
IMPORTANT
任务2:内核启动后执行第一个用户态程序 src/user/init.S。在 src/kernel/core.c 的 kernel_entry() 中手动创建并启动第一个用户态进程。(即将 init.S 的代码映射到进程的 section 中)。
INFO
提示:可以在core.c中使用 extern char icode[]; extern char eicode[]; 来获得 init.S 的代码段的内核地址。这样的操作我们在 Lab 0 中清空 BSS 段时也用过。
实现成功后,内核将输出 shell 的 prompt($)。此时,你仍然无法与内核交互,下面我们将实现 console,支持用户输入命令,运行程序。
4. Console
在开发中,我们常常使用诸如 printf(), getchar() 等标准库函数实现用户输入与交互。然而,截至目前,我们的内核尚未支持键盘输入功能。因此,基于前一部分已实现的 shell,我们将进一步扩展功能,设计和实现 console,使用户能够通过键盘输入与 shell 交互,从而执行相关命令和运行硬盘上的程序。
当用户通过键盘输入内容时,内核会接收到 UART 触发的中断。通过读取 UART 的相关寄存器(由 uart_get_char() 实现),我们可以获得用户输入的具体字符。以下是 UART 的中断处理函数:
static void uartintr()
{
/**
* Invoke the console interrupt handler here.
* Without this, the shell may fail to properly handle user inputs.
*/
char c = uart_get_char();
if (c != 0xFF) {
console_intr(c);
}
device_put_u32(UART_ICR, 1 << 4 | 1 << 5);
}在中断处理流程中,我们首先通过 uart_get_char() 获取用户输入的字符 c,然后将其交由 console_intr 函数处理。中断处理完成后,通过 device_put_u32 清除 UART 的中断状态。
console 是一个被抽象为文件的设备,主要管理用户输入的数据,即输入/输出缓冲区。在 console_intr 函数中,用户输入的字符会写入 console 的缓冲区,成为 console 所管理的核心数据。
正如之前所提到的,“一切皆文件”的设计理念使我们能够通过统一的接口对各种资源进行操作。在本实验中,用户态的 shell 通过内核提供的 read 和 write 接口,通过读写 console,实现与用户的交互。
具体来说:
- 读取用户输入:shell 调用
read接口,从缓冲区读取用户输入的字符。通过读取这些字符,shell 可以解析并执行用户输入的命令,例如echo hello。在这种情况下,shell 会理解用户是希望以hello为参数运行echo程序。 - 输出到终端:shell 调用
write接口,将需要显示的内容写入缓冲区。内核会从缓冲区中读取这些内容,并通过 UART 将其输出到终端供用户查看。
回显
用户在终端中输入命令时,需要实时看到自己输入的内容。例如用户输入命令 ls -al的同时,终端会显示出用户输入的命令,避免用户像输入密码一样“盲打”,给用户带来了良好的交互体验。
原理:当用户在键盘上输入字符时,内核会触发 UART 中断,执行以下流程:用户键盘输入 -> 内核的 UART 中断 -> console_intr(c) -> 将 c 写入缓冲区 -> uart_put_char(c) 回显给用户。
索引
struct console 定义了三个重要的索引,用于跟踪缓冲区的状态:
read_idx:标识已被用户态(通过调用 read 的 shell)读取的位置。write_idx:标识已被用户态(通过调用 write 的 shell)写入的位置。edit_idx:标识当前用户编辑的光标位置。
4.1. 任务
IMPORTANT
任务 1:完成 console_intr,处理下述情况:
backspace:对应字符c为\x7f。删除前一个字符,即input.edit_idx--。注意,位于input.write_idx前的已回显字符不能删除。Ctrl+U:删除一行。Ctrl+D:更新input.write_idx到input.edit_idx。表示EOF。本身也要写入缓冲区和回显。- 普通字符写入和回显。
回显会用到 uart_put_char 向console写入内容。
IMPORTANT
任务 2:完成 console_read 和 console_write,并在 inode_read 和 inode_write 中调用(前面我们已经提到,我们复用了 inode 作为设备文件的抽象)。
INFO
提示:可以参考 xv6 console 的实现。
5. Pipe
相信到目前为止,你已经对“一切皆文件”的哲学有了较深的理解。在本部分,你将在“一切皆文件”哲学的指导下,实现 pipe。
在 Linux 中,pipe(管道) 是一种进程间通信(IPC, Inter-Process Communication)机制,用于将一个进程的输出直接作为另一个进程的输入。它通过一种“生产者-消费者”模型实现数据流的传递,主要用于命令之间的协作,避免使用临时文件。
管道的创建与使用
在 Shell 中使用管道:管道符号是
|,将前一个命令的输出传递给后一个命令作为输入。例如:shellls -l | grep "txt"其中,
ls -l列出了当前目录的详细信息,而grep "txt"过滤包含 txt 的文件。该命令的作用是筛选出当前目录下的txt文件。pipe()是一个低级系统调用,用于创建一个匿名管道。它返回两个文件描述符:读端pipefd[0]和写端pipefd[1]。c#include <unistd.h> #include <stdio.h> #include <string.h> int main() { int pipefd[2]; char buffer[128]; if (pipe(pipefd) == -1) { perror("pipe"); return 1; } // 写入管道 write(pipefd[1], "Hello, Pipe!", strlen("Hello, Pipe!") + 1); // 读取管道 read(pipefd[0], buffer, sizeof(buffer)); printf("Read from pipe: %s\n", buffer); return 0; }
5.1. 任务
IMPORTANT
任务1:完成 pipe.c 中的内容。
IMPORTANT
任务2:完成 sysfile.c 中的 pipe2,实现相关系统调用。
INFO
提示:可以参考 xv6 pipe 的实现。
6. Memory Management
本次实验为初步了解一些用户态程序的内存管理功能。包括修改程序堆的大小、Lazy Allocation 和 Copy on Write。
6.1. 基础知识
6.1.1. ELF格式和段
ELF 是一种用于二进制文件、可执行文件等文件的文件格式,是 Linux 的主要可执行文件格式。ELF 格式将可执行文件分成几个不同的section,一个程序主要由 anonymous 段和 file-backed 段组成:
anonymous段:执行时才会创建的段,可执行文件本身不包含,比如bss(减少文件大小)、stack(执行时才能确定其中的内容)。file-backed段:可执行文件本身就拥有的段,比如text(可执行文件的代码段)、data(已初始化的数据段)。
其中从 text 到 stack,对应的虚拟地址一般是逐渐增加的(见下图)。我们可以通过 size 命令查看一个可执行文件的各个段的大小。
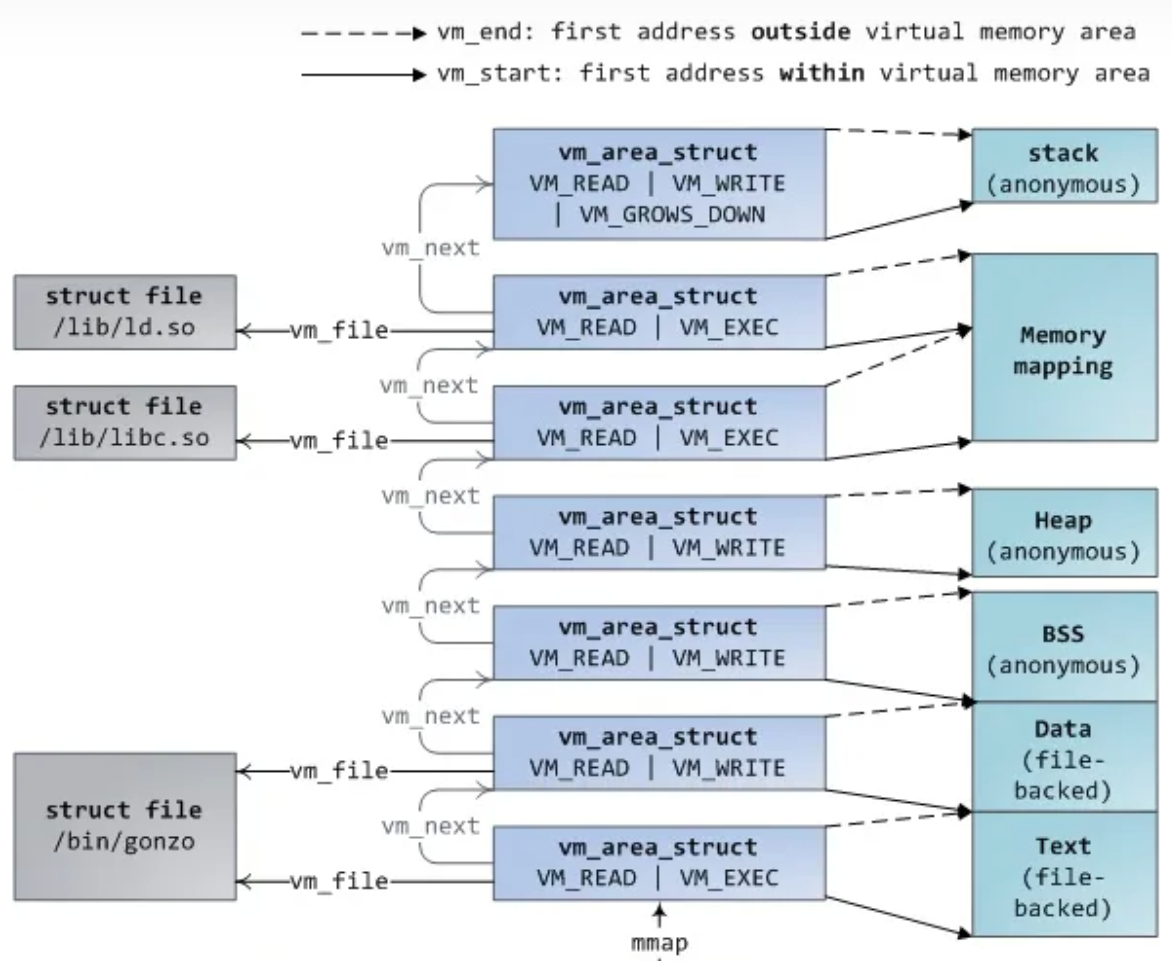
我们实验中同样采用段(struct section对应于上图中的vm_area_struct)的数据结构来标识一个可执行文件在执行时拥有的各类段的信息。
6.1.2. 虚拟内存
虚拟内存机制有如下特性:
- 隔离性:虚拟内存使得操作系统可以为每个应用程序提供属于它们自己的地址空间,所以一个应用程序不可能有意或者无意的修改另一个应用程序的内存数据,我们在进行本次实验时也需要保证这一点。
- 抽象性:进程运行时用虚拟地址,而内核会定义从虚拟地址到物理地址的映射关系,因此进程的运行就无需关注和管理对应的物理内存,这是我们这节课要讨论的许多有趣功能的基础。
- 灵活性:目前的内存映射都是静态的,即我们初次配置完页表后,以后不会再修改页表中映射关系。前面我们提到,AArch64 存在多张页表,分别用于不同的异常级别:
- 内核态映射:即内核使用的页表。此页表已硬编码在框架代码中(
aarch64/kernel_pt.c),后续也不会再修改。 - 用户态映射:在先前的实验中,我们针特定测试(如
userproc中的loop)手动设置了用户页表,确保不会出现 Page Fault。
- 内核态映射:即内核使用的页表。此页表已硬编码在框架代码中(
可以发现,前面的实验中,我们的(用户)页表都是静态的,即设置完成后不会在进程的生命周期内动态修改。然而,经过理论课的学习我们知道,许多重要的内存管理机制(如 Lazy Allocation,Copy on Write,Demand Paging 等)都依用户页表的动态更新。我们需要通过 Page Fault,引导内核更新页表,动态调整用户态进程的地址映射,提高系统内存的灵活性
INFO
我们可以通过 (h)top 指令查看进程以及内存的使用情况(比如在 top 命令中,VIRT 表示的是虚拟内存地址空间的大小,RES 是实际占用的内存数量),我们发现进程的虚拟地址往往比他们拥有的多,倘若直接把所有的进程的虚拟地址都分配物理页的话,会大幅度降低内存利用率,这是动态分配内存的一个重要优点。
6.1.3. Page Fault
顾名思义,Page Fault 就是让用户进程在执行时触发异常,陷入到内核态进行处理,从而让内核动态地管理内存,而当内核处理 Page Fault 时,可能会用到如下信息:
- 引起 Page Fault 的内存地址(
far寄存器) - 引起 Page Fault 的原因类型(
esr寄存器) - 引起 Page Fault 程序计数器值(
elr寄存器)
借助 Page Fault,我们能够实现如下几个功能:
- Lazy Allocation
- Copy on Write
- Demand Paging (Final Lab)
Lazy Allocation
C语言中动态内存分配的基本函数是 malloc,在 Linux 上,malloc 实现通常会根据需要选择使用 brk/sbrk 或 mmap (涉及分配较大的块,映射文件或设备)系统调用来分配内存。这里我们主要关注 sbrk 系统调用。
uint64
sys_sbrk(void)
{
uint64 addr;
int n;
argint(0, &n);
addr = myproc()->sz;
if(growproc(n) < 0)
return -1;
return addr;
}以上是 xv6 中 sbrk的实现,其中调用了 growproc 函数,直接分配给应用程序需要的物理内存。
直接分配会导致大量内存的的浪费,更好的做法是只增加段的 size,等到进程执行到对应地址时会触发 Page Fault,这时我们再调用 kalloc_page 申请物理页,并根据出错的虚拟地址(需要的信息)建立映射。
INFO
虚拟内存中提到的抽象性:每个应用程序都觉得自己占有了全部的硬件资源(但实际上并不是),而且应用程序来说很难预测自己需要多少内存,所以通常来说,应用程序倾向于申请多于自己所需要的内存。
Copy on Write (Zero Fill On Demand)
我们先从一个比较简单的例子入手。我们知道,BSS 段包含了未被初始化或者初始化为 0 的全局变量。为了节省空间,可执行文件一般不包含这个其中的内容,只在其被执行时,内核才创建对应的内容。
BSS 段初始的内容全部为 0,同时每个进程又有 BSS 段,因此不难想到一个优化点:在物理内存中,分配一个 page,page 内容全是0,然后让所有虚拟地址空间的全 0 的 page 都映射到这一个物理 page 上,这样至少在程序启动的时候分配时节省大量的物理内存分配。
还记得之前提到的隔离性吗?不同进程的 BSS 段实际上是不能完全共享的,因此要注意不能写,也就是说对应的页表项必须设置为只读;因此,当进程尝试往 BSS 段写入数据时,会触发 Page Fault,此时我们应该如何处理?
创建一个新的 page,将其内容设置为
0,并重新执行指令(当然还要把页表项设为可读写)
当然有所得必有所失,不足之处在于每次写入都触发 Page Fault,而 Page Fault 涉及用户态和内核态的交互,试想一下原本只用配置 BSS 段一遍,如果运气不好的话, BSS 段中每页都要触发 Page Fault,这样的效率是很低的。
Copy on Write (Fork)
另外一种写时复制的应用场景,那就是 fork 时的 Copy on Write。
INFO
当 shell 处理指令时,它会通过 fork 创建一个子进程。该子进程执行的第一件事情就是调用 exec 运行一些其他程序,而 exec 做的第一件事情就是丢弃自身地址空间,取而代之的是一个包含了要执行的文件的地址空间。
当我们用 fork 创建子进程时,可以不立刻创建、分配并拷贝内容到新的物理内存,而是先共享父进程的物理内存空间。
和 Zero Fill On Demand 的场景同样,一旦一个进程往对应的页面写入时应该怎么办?
创建一个新的 page,复制之前的内容,并重新执行指令(当然还要把页表项设为可读写)
当一个进程退出时需要怎么处理?
进程退出时会释放其所有的页面,但是,实际上该页面本身可能不能直接释放,因为其可能正在被多个进程使用,因此我们需要对 page 进行引用计数,当我们释放虚拟内存时,我们将 page 的引用数减
1,如果引用数等于0,此时我们才能释放对应的物理内存。
struct page {
atomic_t count;
};
struct pages[page_total]; // 根据页面的物理地址找到所属的页面
kalloc_page: refcnt = 1
kfree_page: refcnt -= 16.2. 实验内容
有关的结构体:
struct page {
RefCount ref;
};对于每个页面,我们记录它的引用数。当且仅当引用数为 0 时,页面应该被释放。
struct section {
u64 flags;
u64 begin, end; // [begin, end)
ListNode stnode;
};对于程序的每个段,我们将它的起始地址、结束地址和 flags 记录在结构体中。
struct pgdir {
PTEntriesPtr pt;
SpinLock lock;
ListNode section_head;
}然后将每个段的结构体以链表的形式连接起来,保存在进程的 pgdir 中。这样我们就能知道每个进程的每个段的区间。
所有的 Flags 如下:
#define ST_FILE 1 // File-backed
#define ST_SWAP (1<<1) // Unused, 如果你想写swap可以用
#define ST_RO (1<<2) // Read-only
#define ST_HEAP (1<<3) // Section is heap
#define ST_TEXT (ST_FILE | ST_RO) // Section is text
#define ST_DATA ST_FILE // Section is data
#define ST_BSS ST_FILE // Section is bss6.3. 任务
IMPORTANT
任务 1:准备用户程序堆并实现 sbrk() 系统调用
**用户程序堆:**我们需要在初始化进程时为进程创建一个初始大小为 0 的堆,并将该 section 记录在进程的 pgdir 中。堆的起始地址一般取决于用户程序内存空间 layout,但由于本次实验不涉及其他段,暂时可以随意制定一个(合法的)堆的起始地址。
sbrk()系统调用:该系统调用的功能是 Set Program Break,即设置进程的堆的终止位置。
WARNING
本次实验中暂不需要在SYSCALL_TABLE中注册该系统调用
函数模板:
u64 sbrk(i64 size);size:堆大小的增加量(字节),可以为负数。- 返回值:原来(修改前)的堆终止位置的地址,如果参数非法则返回
-1。
**实现思路:**当用户程序调用 sbrk() 时,我们需要将堆的终止位置增加 size,并返回修改前的堆终止位置的地址。我们将新的堆终止位置记录在 section 结构体中,并通过 Lazy Allocation 的方法来实现新的页的分配。
IMPORTANT
任务 2:实现 Lazy Allocation 和 Copy on Write。
Lazy Allocation
WARNING
在本实验中,我们只需要关注 heap 段。其他段会在后续实验中涉及。
- 当用户程序调用
sbrk()时,我们并不需要立即将新的页分配给用户进程,只须把新的 heap 终止位置记录到对应的section结构体中即可。 - 这样,当用户程序访问到新的 heap 时,会触发缺页异常,我们在缺页异常处理程序中,判断缺页地址是否在 heap 中,如果是,说明应当是 Lazy Allocation 的情形。(这种判断方法是否严谨?)
- 这时分配一个新的页,将这个页分配并映射给用户进程,再返回用户进程继续执行即可。
- 如果不是,则这是一个非法内存访问,应该杀死用户进程并报错。
- 特别注意,
sbrk()不仅可以增加 heap 的大小,还可以减小heap的大小(也可以不变)。减小时应该如何处理?
Copy on Write
WARNING
在后续实验中,我们会在创建bss段和 fork() 时使用 Copy on Write。
- 我们在系统启动时分配出来一个页,将其内容初始化为全零。我们将该页指定为共享全零页,每次有进程需要创建一个全零页时,我们创建一个到共享全零页的只读映射即可。需要保证该页永远不会被释放。
- 如果进程需要对全零页进行写入操作时,会触发缺页异常。同样地,我们可以在缺页异常处理程序中判定这是否是 Copy on Write 的情形。
- 如果是,我们分配一个新的页,将共享全零页的内容拷贝过去(也就是将新的页全设为零),然后将新页映射给用户进程,再返回用户进程继续执行即可。
- 如果不是,则这是一个非法内存访问,应该杀死用户进程并报错。
相关函数
int pgfault_handler(u64 iss) {
struct proc *p = thisproc();
struct pgdir *pd = &p->pgdir;
u64 addr = arch_get_far(); // Attempting to access this address caused the page fault
// TODO:
// 1. Find the section struct that contains the faulting address `addr`
// 2. Check section flags to determine page fault type
// 3. Handle the page fault accordingly
// 4. Return to user code or kill the process
}这是缺页异常处理程序,在trap_global_handler中,我们需要判断trap是否是缺页异常,如果是,则交由这个函数处理。
void vmmap(struct pgdir *pd, u64 va, void *ka, u64 flags) {
// TODO
// Map virtual address 'va' to the physical address represented by kernel
// address 'ka' in page directory 'pd', 'flags' is the flags for the page
// table entry
}在pd中将虚拟地址va映射到内核地址ka对应的物理地址:
WARN_RESULT void *get_zero_page() {
// TODO
// Return the shared zero page
}返回共享全零页。
DANGER
**特别提醒:**修改页表后需要调用arch_tlbi_vmalle1is()以清空 TLB 。忘记清空 TLB 将引发难排查的 BUG 。
7. File Mapping
什么是 mmap() ?
mmap,从函数名就可以看出来这是memory map,即内存映射,是一种内存映射文件的方法,将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。mmap() 系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问,不必再调用 read() ,write() 等操作。
为什么要用 mmap() ?
Linux通过内存映像机制来提供用户程序对内存直接访问的能力。内存映像的意思是把内核中特定部分的内存空间映射到用户级程序的内存空间去。也就是说,用户空间和内核空间共享一块相同的内存。这样做的直观效果显而易见:内核在这块地址内存储变更的任何数据,用户可以立即发现和使用,根本无须数据拷贝。举个例子理解一下,使用 mmap 方式获取磁盘上的文件信息,只需要将磁盘上的数据拷贝至那块共享内存中去,用户进程可以直接获取到信息,而相对于传统的 write/read IO 系统调用, 必须先把数据从磁盘拷贝至到内核缓冲区中(页缓冲),然后再把数据拷贝至用户进程中。两者相比,mmap 会少一次拷贝数据,这样带来的性能提升是巨大的。
参考资料:XV6学习(15)Lab mmap: Mmap - 星見遥 - 博客园
7.1. 任务
IMPORTANT
任务 1:实现下列系统调用。
void *mmap (void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length);8. bonus
同学可以自己就一个感兴趣的系统组建进行功能扩充。
9. 构建、测试与提交
git fetch --all
git checkout final
git checkout -b final-dev
git merge lab6-dev在拉取了最新的框架后,我们需要:
git submodule update --init在构建时,我们需要:
cd build
cmake ..
make libc -j
make qemu当你完成全部任务后,如果一切顺利,将进入 shell,你可以自己运行里面的程序。我们也编写了一个 usertests 程序供测试。
提交日期为 2026 年 1 月 26 日,如有特殊情况请联系助教。
 tangxiaoxia0336
tangxiaoxia0336